 Antivirus
Antivirus
A cryptographic hash function – often referred to simply as a hash – is a mathematical algorithm that transforms any arbitrary block of data into a string of new characters of a fixed length. Regardless of the length of the input data, the same type of hash will always output a hash value of the same length.
So, according to an online, SHA-1 hash generator (SHA-1 is one of the most widely deployed hash functions in computing, along with MD 5 and SHA-2), the hash for my name, Brian, is: 75c450c3f963befb912ee79f0b63e563652780f0. As probably any other Brian can tell you, ‘brain’ is an incredibly common misspelling of the name. So common in fact, I once had an official driver’s license on which my name was spelled, “Brain Donohue,” but that’s another story. The SHA-1 hash for brain, again according to my online SHA-1 generator, is: 8b9248a4e0b64bbccf82e7723a3734279bf9bbc4.
As you can see, those two outputs are quite different, despite the fact that the difference between the name Brian and the word for the organ at the center of your central nervous system depends entirely on the arrangement of two consecutive vowels (‘ia’ versus ‘ai’). To push this point even further, if I input my name without capitalizing the first letter, the SHA-1 generator again returns a vastly different hashed result: 760e7dab2836853c63805033e514668301fa9c47.
You’ll notice that all the hashes here are 40 characters long, which is unsurprising given that in each case the input is five characters long. However, more surprisingly, entering every word of this story so far into the hash generator returns the following hash: db8471259c92193d6072c51ce61dacfdda0ac3d7. That’s some 1,637 characters (with spaces included) condensed down – just like the five-character words above – into a 40 character output. You could SHA-1 hash the collected works of William Shakespeare and still end up with a 40-character output. Furthermore, no two inputs yield the same hashed output.
Here’s a picture courtesy of Wikimedia Commons illustrating the same concept for those of you who prefer visual learning:
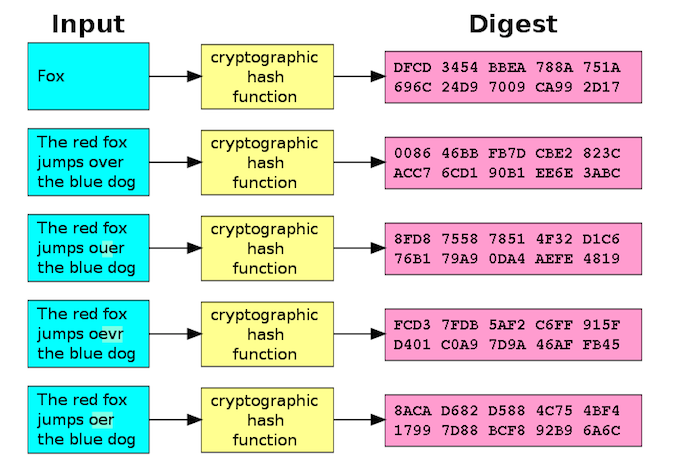
What are hashes used for?
Great question. Unfortunately, the answer is that crypto hashes are used for a whole lot of things.
For me and you, the most common form of hashing has to do with passwords. For example, if you ever forget your password to some online service, you will likely have to perform a password reset. When you reset your password, you generally don’t receive your plaintext password in return. That’s because the online service doesn’t store your plaintext password. They store a hash value for that password. In fact, that service (unless you are using an incredibly simple password for which the hash value is widely recognized) has no idea what your real password is.
To be clear, if you do receive your plaintext password in return, that means that the online service you are using isn’t hashing your password and shame on them.
You can test this yourself with an online reverse hash generator. If you generate a hash value for a weak password like “password” or “123456” and then enter that hash value into a reverse hash generator, chances are the reverse hash generator will recognize the hash value for either of those passwords. In my case, the reverse hash generator recognized the hashes for ‘brain’ and ‘Brian’ but not the hash that represents the body of this text. So the integrity of a hash output is entirely dependent on the input data, which can be literally anything.
On that point, according to a report from TechCrunch late last month, the popular cloud storage service, Dropbox, blocked one of its users from sharing content protected under the Digital Millennium Copyright Act (DMCA). This user tweeted that he had been blocked from sharing certain content, and Twitter blew up a bit with people shouting and screaming about how Dropbox must be rifling through user content despite promising not to do exactly that in its privacy policy.
Dropbox, of course, did not rifle through any user content. As noted by the TechCrunch article, what likely happened here is that the copyright holder took their copyrighted file (perhaps the digital makeup of a song or movie) and passed it through a hash function. They then took the output hash value and added that series of forty characters to some sort of denylist for the hashes of copyright-protected materials. When the user tried to share this copyright-protected material, Dropbox’s automated scanners picked up on the denied hash and blocked it from being shared.
So, you can clearly hash passwords and media files, but what other purposes do cryptographic hash functions serve? Again, the true answer is that hash functions serve more purposes than I know, understand, or care to write about. However, there is one more hashing application that is close to our hearts here at the Kaspersky Daily. Hashing is widely deployed in the practice of malware detection by Antivirus firms like Kaspersky Lab.
Sort of in the same way that movie studios and record labels create hash denylists to protect copyrighted data, there are any number of malware hash value denylists as well, most of which are publicly available. These malware hash – or malware signature – denylists consist of the hash values of malware or the hash values of smaller and recognizable components of malware. On the one hand, if a user finds a suspicious file, that user can enter its hash value into one the many publicly available malware hash registries or databases, which will inform the user as to whether the file is malicious or not. On the other hand, one way antivirus engines recognize and ultimately block malware is by comparing file hashes to their own (and also public) malware signature repositories.
Cryptographic hash functions are also used to ensure something called message integrity. In other words, you can ensure that some communication or a file has not been tampered with by examining a hash output generated both before and after the data transmission. If the before and after hashes are identical, then the transmission is said to be authentic.

 Tips
Tips